

안녕하세요, 메이아이의 Lead Researcher 박진우입니다.
'daram과 함께하는 딥러닝 투어 (3)'에서는 물체 추적 기술의 전반적인 내용과 함께, 오프라인 공간에서 나타나는 물체 추적 기술의 도전 과제 및 해결 방안을 간략하게 소개해 드렸습니다. 2편의 내용을 간단히 돌이켜 보자면, 물체 추적 기술(Object Tracker)이란 연속된 이미지들에서 동일한 객체로 판단되는 물체들의 프레임 간 위치를 이어주는 기술이었습니다. 대표적인 물체 추적 모델 SORT에서는 지난 프레임에서의 물체 위치를 바탕으로 물체의 다음 위치를 예측하고, 해당 예측과 가장 비슷한 물체를 이어주는 방식으로 동작했습니다. 이 SORT는 원리에 비해 매우 강력한 물체 추적 기술이지만, 실제 환경에서는 ID Switching, Tracklet Fragments 발생, Multi-Camera Tracking과 같은 추가적인 문제들이 남아있어서 추가적인 기술 연구가 진행되고 있다는 점을 알 수 있었습니다. 지난 내용을 통해 기존에 딥러닝에 친숙하지 않으셨던 분들도 물체 추적이라는 분야와 daram에 대해 조금 더 쉽게 다가갈 수 있는 기회가 되셨을 것이라고 생각합니다.
이번 포스팅에서는 지난 물체 추적 기술 소개에서 잠시 소개 드렸던 Multi-Camera Tracking, 즉 여러 서로 다른 카메라 간의 물체 추적 기술의 핵심을 이루는 재식별 기술(Re-Identification)의 기초적인 내용을 소개하겠습니다.
Re-Identification 소개
지난 포스팅에서 언급했듯 실제 오프라인 공간에서는 하나의 영상 내에서 물체를 추적하는 것도 중요하지만, 더 고도화된 분석을 위해 하나의 영상이 아닌 여러 대의 카메라에서 얻은 여러 개의 영상에 걸쳐 동일 물체를 추적하는 기술이 필요합니다. 이 기술을 보통 일반적인 추적(Tracking) 기술과 구별해서 Multi-Camera Tracking이라고 합니다.
두 기술을 구분하는 이유는 단순히 Multi-Camera Tracking이 난이도가 더 높기 때문만은 아닙니다. 물체 추적이라는 개념적인 측면에서는 동일하지만, 세부적인 구현 원리와 주요 기술에 꽤나 큰 차이가 있습니다. 물체 추적 기술에서는 물체의 위치가 추적에 사용되는 중요한 요소(factor)인데요. 다수의 카메라에서 물체를 추적하는 경우에서는 화면 내 물체의 위치가 그다지 추적의 힌트가 되지는 않습니다. 예를 들어 입구에 설치된 카메라에서 화면의 오른쪽 아래 방향으로 물체가 움직였다고 해서, 다른 카메라에서 해당 물체가 화면의 오른쪽 아래 방향에 있는 건 당연히 아닐 거라고 쉽게 추론할 수 있습니다. 물론 이론 상으로는 카메라가 설치된 위치를 알고 있다는 가정 하에, 추가적인 매칭 기법을 통해 특정 물체의 실제 세계 상 좌표, 소위 World Coordinate을 알 수는 있고 이를 이용하여 Multi-Camera Tracking을 구현하는 프로젝트도 실제로 존재합니다. 하지만, 이 매칭 과정을 현실적으로 모든 분석 장소에 적용하는 것은 굉장히 힘들고 많은 비용이 드는 일입니다.
따라서 Multi-Camera Tracking 기술에서는 재식별 기술(Re-Identification)을 통해 동일한 물체 여부를 판단하게 됩니다. 본 편에서는 재식별 기술에 대한 기본적인 설명과 함께 재식별 기술을 실제 오프라인 공간 분석에 사용할 때 생기는 실용적인 이슈들, 마지막으로 Multi-Camera Tracking 기반의 데이터 분석 예시에 대해 소개 드리도록 하겠습니다.
Re-Identification의 원리
앞서 말씀드린 바와 같이 Multi-Camera Tracking을 구현하기 위해서 물체의 위치를 사용하기에는 현실적인 어려움이 너무나 많습니다. 따라서 여러 대의 카메라 간 물체 추적 기술의 경우 물체의 위치보다는 물체의 형태 면에서 얼마나 비슷한 지를 집중적으로 체크해야 합니다.
예를 들어 흰 티셔츠에 검은색 가방을 메고 베이지색 바지를 입은 사람의 동선을 추적한다고 하였을 때, 다른 카메라에서도 같은 형태와 같은 색상의 복장을 한 사람을 찾은 다음 티셔츠는 얼마나 비슷한 지, 가방은 얼마나 비슷한 지, 바지는 얼마나 비슷한 지를 체크해서 가장 비슷한 사람을 동일한 사람이라고 추측하는 형태입니다. 이 과정을 인공지능 기술적인 용어를 사용하여 설명하면, 두 대의 다른 카메라에서 물체 이미지를 추출하고, 해당 이미지의 시각적 특징 (Visual Feature)을 임베딩 벡터(embedding vector) 형태로 추출하여 두 벡터 간 거리가 가까운 정도를 체크한다고 말할 수 있습니다.

이렇게 이미지를 입력받은 다음, 이 이미지의 '인물 구분을 위한' 시각적 특징들을 수학적인 임베딩 벡터 형태로 내보내는 기술을 바로 재식별(Re-Identification)이라고 합니다. 여기서 시각적 특징은 위에서 말씀드린 복장 및 체형 등을 포함하고 있는 복합적인 인물의 모습이고, 임베딩 벡터란 이 인물의 특징을 수학적인 계산이 가능하도록 벡터 형태로 나타내는 것이라고 이해하시면 됩니다.
임베딩 벡터에 대한 설명이 어려운 것 같아 간단한 예시를 들어보겠습니다. 128개의 칸을 가진 임베딩 벡터를 이용하여 인물의 특징을 나타낸다고 할 때, 임베딩 벡터의 첫 번째 칸은 상의의 형태, 두 번째 칸은 상의의 색, 세 번째 칸은 하의의 형태와 같이 고유한 의미들을 담고 있습니다. 그리고 각각 칸에 담겨있는 숫자가 해당 칸의 ‘정도’나 ‘종류’를 나타내고 있는 것입니다. 예를 들자면 파란색 상의의 경우 두 번째 칸의 값이 0.854 정도, 붉은 계열 상의의 경우 반대로 0에 더 가까운 0.178의 값을 가지는 임베딩 벡터가 할당됩니다.
물론, 임베딩 벡터 각각의 칸이 위와 같이 명시적인 하나의 속성만을 나타내는 것은 아닙니다. 오히려 좀 더 복합적인 의미, 예를 들면 '캐주얼한 느낌의 사람'이라던가, '키가 크고 호리호리한 느낌'과 같이 다양한 속성이 복합적으로 섞인 특성을 나타내고 있는 쪽에 가깝고, 우리는 그 의미를 명확히 알지 못합니다. 보통 인공지능 모델에 대해 설명할 때 우리가 모델의 동작 원리나 세부적인 내부 정보에 대해 명확히 알 수 없다는 의미로 'black-box'라 표현하는 예시를 자주 볼 수 있는데요. 이 임베딩 벡터의 부분이야말로 확실히 black-box라는 표현이 어울리는 것 같습니다.
위와 같이 임베딩 벡터가 주어지면, 우리는 수학적인 계산을 통해 여러 임베딩 벡터들이 얼마나 유사한 값을 가지고 있는지를 0에서 1 사이의 값으로 나타낼 수 있습니다. 이러한 수학적 유사도 측정의 대표적인 계산법인 코사인 유사도(Cosine Similarity)를 두 임베딩 벡터 간 측정했을 때, 이 값이 0.75가 나왔다면 우리는 두 사람이 조금 높은 확률로 동일한 사람이라 가정할 수 있습니다. 이러한 원리를 활용하여 최종적으로 Multi-Camera Tracking을 구현하는 방법은 다음과 같습니다. 먼저 여러 대의 카메라가 각각의 카메라에서 얻은 영상 내에서, 일반적인 Object Tracking 기술을 활용하여 인물들을 추적합니다. 그 후 어떠한 특정 값 (ex. 0.6)을 동일 인물 여부를 판단하기 위한 최솟값(Threshold)이라 설정하고, 각각의 카메라에서 추적된 모든 사람들의 쌍에 대해 서로 간의 유사도가 위의 최솟값을 초과하는지 혹은 미만인 지를 체크합니다. 그다음으로는 위와 같은 유사도 측정을 통해 각각의 인물들 간 동일인 여부가 이어지게 되면, 서로 이어진 관계도를 따라가며 최종적인 동일인 동선 그룹의 원소(member)로 넣어 고유한 식별 번호를 붙이게 됩니다. 여기까지 완료되면 마지막으로 동선 내 원소들을 등장 시간에 맞춰 정렬하거나 기타 추가적인 인터랙션 정보 등을 붙여서 실제 분석에 사용하게 됩니다.
Re-Identification의 과제, Domain Adaptation
위와 같이 재식별 기술을 활용하여 Multi-Camera Tracking 기술을 구현하는 대략적인 방안에 대해 살펴보았습니다. 그렇다면 다음으로 의문을 가질 만한 부분은 이러한 임베딩 벡터를 추출하는 인공지능 모델을 어떻게 만드는지를 궁금해할 수 있습니다.
사실 인공지능 분야에는 데이터 간의 유사도를 수치화하는 거리 함수를 학습하는 Metric Learning이라는 방법론이 있어서, 사람 간의 유사도를 측정하기 위한 임베딩 벡터를 추출하는 재식별 기술 또한 이 Metric Learning 방법론을 활용하여 학습을 진행합니다.
Metric Learning의 가장 간단한 방법은 딥러닝 분야에서 가장 기초적인 모델인 분류(Classification) 모델을 이용하는 것입니다. 인공지능 분류 모델의 경우 퍼셉트론이라고 부르는 구조를 여러 층으로 쌓은 뒤 가장 마지막의 분류 층의 결과 벡터를 각 class 별 확률값을 담고 있도록 설계하는데, 이 과정에서 마지막 층 바로 직전 층의 결과 벡터는 굉장히 많은 정보를 내재하고 있는 벡터로 자연스럽게 학습됩니다. 이러한 특징을 이용해서, ‘동일 인물의 구분’을 위한 정보를 최대한 많이 가지도록, ‘동일 인물’을 ‘구분’하는 분류 모델을 설계하고 학습한 뒤, 가장 마지막의 분류를 위한 층만 제거해서 임베딩 벡터를 사용하는 방식으로 재식별 모델을 학습할 수 있습니다.
다만 위와 같은 방법에는 커다란 문제가 존재합니다. 바로 재식별 모델을 위해 ‘동일 인물’을 ‘구분’하는 분류 모델을 설계하고 학습해야 한다는 점인데요. 이 과정에서 학습 데이터셋의 문제가 있습니다. 당연히 여러 인물들에 대해서도 동일 인물 여부를 잘 구분하려면 인공지능 모델이 최대한 많고 다양한 인물들을 보는 것이 중요한데요. 바로 그것을 위해 동일 인물을 미리 다 판별해 놓은 '정답 데이터셋'을 구하는 것이 굉장히 어렵다는 점입니다.
좀 더 자세히 설명하자면 크게 두 가지 어려움이 있습니다. 첫 번째 어려움은 이러한 동일 인물 데이터셋을 만들기 굉장히 어렵다는 점에 있습니다. 가령, 넓은 공간, 예를 들면 백화점의 각 구역들마다 설치된 CCTV 카메라에서 영상을 추출한 뒤, 위와 같은 동일 인물 데이터셋을 만들어 보는 과정을 상상해 보겠습니다. 먼저 CCTV 카메라에서 인물들을 전부 추적하면 수백, 수천에서 많게는 수만 명의 인물 이미지들이 확보됩니다. 그다음은 이 인물들을 동일 인물들을 같은 폴더에 넣어주는 작업을 하는 것과 비슷한 일을 하게 되는데, 이때 수많은 이미지 중에서 한 이미지(인물)을 선택한 뒤, 해당 이미지를 제외한 나머지 이미지에서 동일한 사람을 찾아 전부 체크합니다. 이 과정을 수만 명의 인물 이미지들에 대해 반복하는 작업이니, 정말 많은 이미지가 확보되어야 합니다. 이 과정을 줄이기 위해서는 미리 촬영 대상자들끼리 경로를 정해둔 시나리오를 따르도록 할 수도 있겠지만, 그렇게 되면 일단 경로의 다양성이나 인물의 다양성 면에서 구분력이 높은 모델을 학습하기에 충분하지 않을 수 있습니다.
두 번째 어려움은 바로 오픈 데이터셋의 부재와 도메인 간 성능 격차가 크다는 사실입니다. 사실 오픈 데이터셋이 많이 있고, 도메인 간 격차가 크지 않아 한곳에서 학습한 모델을 다른 장소들에서도 문제없이 사용할 수 있다면 장소 별로 데이터셋을 만들 필요가 없겠지만, 안타깝게도 재식별 모델은 한 장소에서 학습한 모델을 다른 장소에서 아무런 추가 기법 없이 그대로 사용했을 때 성능이 굉장히 떨어지는 편이라는 것을 많은 논문들에서 확인할 수 있습니다. 예를 들어 아래 표를 보시면, Duke-MTMC -> Market-1501의 경우 Duke-MTMC에서 학습한 모델을 그대로 Market-1501 데이터셋에 적용했을 때의 성능으로, 원래의 데이터셋을 학습했을 때 mAP 70 이상이 나오는 것과 비교하면 굉장히 낮은 성능을 보입니다.

또한, 오픈 데이터셋 면에서도 위에서 말씀드린 것과 같이 애초에 데이터셋을 제작하기 매우 힘든 점이 있을 뿐만 아니라, Duke-MTMC와 같이 이미 공개되었던 오픈 데이터셋도 개인정보보호 이슈로 인해 없어지는 등, 다양한 현실적인 제약이 존재합니다.
위와 같은 문제를 해결하기 위해, 재식별 기술의 트렌드는 기존의 단순한 재식별 성능 향상부터 새로운 도메인에서도 좋은 성능을 낼 수 있도록 하는 도메인 적응 기술로까지 변화했습니다. 특히, 위와 같이 재식별 학습을 위한 데이터셋을 새로 제작하기 굉장히 힘들다는 점에서 데이터셋 라벨링이 필요 없는 비지도 학습 기반의 도메인 적응 기술에 대해 많은 연구에서 다루고 있으며, 메이아이에서도 자체 개발된 비지도 기반 도메인 적응 기술을 통해 지금 분석 중인 다양한 장소에서 재식별화 성능을 좋게 유지하고 있습니다.
Re-Identification을 이용한 데이터 분석
앞의 내용에서 재식별화에 대한 인공지능 기술적인 이슈를 집중적으로 살펴보았다면, 마지막으로는 실제 이러한 재식별화 및 Multi-Camera Tracking 기술을 이용하여 얻은 원천 데이터들을 바탕으로 오프라인 공간 분석을 한 사례에 대해 간단하게 소개 드리고자 합니다.
고객 구매 여정 분석
Multi-Camera Tracking을 활용한 대표적인 분석으로는 고객 구매 여정 분석을 들 수 있을 것 같습니다. 고객 구매 여정 분석은 방문객들의 매장 내 동선을 시각화 및 수치화하는 것으로, 방문객들이 매장에서 어떻게 이동하는지, 그리고 방문객 특성에 따른 동선의 차이를 비교하기 위한 목적의 데이터 분석입니다.
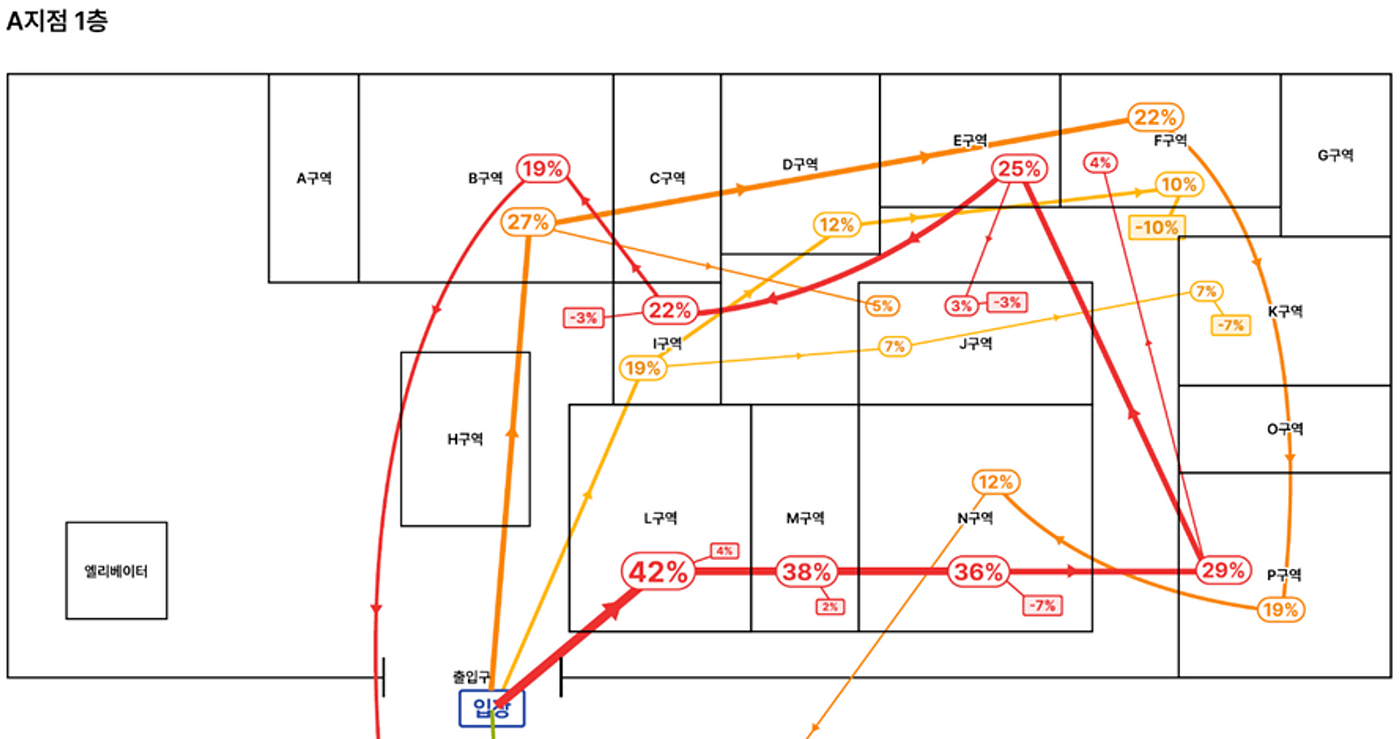
백화점에 위와 같은 동선 분석을 실시하는 예시를 바탕으로 동선 분석의 효용성에 대해 생각해 볼 수 있습니다. Multi-Camera Tracking을 통해 백화점의 매장 관리자가 위와 같은 고객 동선 데이터를 얻게 되면, 매장 관리자는 이를 바탕으로 입점 매장들의 배치를 최적화할 수 있습니다. 예를 들어, 위와 같은 주요 동선 데이터에서 빨간색 동선 살펴보면 P구역 방문객은 이후 높은 확률로 F구역 방문 없이 E구역을 방문하게 되는데, 반대 방향의 주황색 동선을 살펴보게 되면 오히려 E구역 방문 후 F 구역까지 방문한 뒤 P 구역을 방문하는 경향이 있는 것을 파악할 수 있습니다. 즉, 만약 매장 관리자가 F 구역을 E 구역과 묶어서 관리하고 싶다면, 빨간색 동선 방향으로 움직일 때 F 구역 패싱이 일어나니 필요하다면 여러 가지 유도 기법을 사용해서 F 구역의 방문율을 높여야 한다는 점을 알 수 있습니다. 혹은, 기존에 E 구역과 P구역의 관계성이 높지 않다고 생각했다면 몰랐던 새로운 관계성을 알 수 있는 등, 동선 분석을 바탕으로 다양한 분석을 진행해 볼 수 있습니다.
반대로 동선 추적 없이 단순 구역 방문 추정 기술만 사용하는 경우를 생각해 볼 수 있습니다. 이 경우에는 E구역과 P구역의 비율이 비슷하게 높다는 점 정도의 데이터만을 얻을 수 있을 텐데, 단순 비율만으로는 위와 같이 E구역과 P구역의 상관성, 그리고 그 과정에서 E구역과 F구역의 상관성 및 F 구역의 문제점에 대해 파악하는 것은 사실상 불가능합니다.
오프라인 동선 분석의 또 다른 장점으로는, 관심도 단계에서 위와 같은 상관관계 분석이 가능하다는 점입니다. 빅데이터 분석의 사례로 흔히 가장 잘 알려져 있는, 혹은 가장 전설적인 예시로 기저귀와 맥주의 상관관계 분석를 들 수 있는데요. 이러한 분석은 구매 데이터로 이뤄지기 때문에 실제로 구매는 못 했지만 관심도 측면에서의 관계성은 파악이 불가능하다는 단점이 존재합니다. 그러나 영상 기반의 오프라인 고객 여정 분석을 진행하는 경우 관심도 단계에서의 관계성 분석이 가능하며, 바로 이것이 동선 분석 기술과 이를 구성하고 있는 Multi-Camera Tracking 기술의 가능성과 힘이라고 볼 수 있습니다.
동선 샘플링
사실 재식별 기술을 포함한 거의 모든 인공지능 기술의 경우 현재도 다양한 연구가 이뤄지고 있는 아직 완벽하지 않은 기술이라, 실제 환경에 적용했을 때 낮은 확률로 다른 인물들이 동선에 섞이는 등의 작은 오류들이 남아 있습니다. 물체 인식이나 추적 등의 경우에는 이러한 사소한 오류들이 발생하더라도 최종적인 분석에 영향이 매우 적거나, 이후 단계에서 후처리를 통해 정확도를 높이는 방법이 가능한 것에 비해 재식별 모델의 경우 동선 분석 시 서로 다른 인물들이 이어지게 되면 갑자기 없던 구역 간 관계가 예측되는 등 분석에 악영향을 끼치는 정도가 상대적으로 큽니다.
따라서, 메이아이에서는 위와 같은 문제를 원천적으로 차단하기 위해 동선들의 품질을 확인하기 위한 여러 조건들을 통과한 ‘엄선된’ 동선들로만 동선 분석을 진행하고 있습니다. 이러한 ‘샘플링(sampling)’ 과정을 통과한 동선은 일반적으로 방문객 수가 매우 많은 공간에서는 전체 동선의 약 30~50% 정도이며, 사람이 적고 좁은 공간의 경우 60~70% 이상 남아 분석에 이용됩니다. 이 샘플링 과정 전후의 성별/연령 분포 등을 활용하여 샘플링 이전과 이후의 데이터 분포를 비교해 보면 그 분포 차이가 매우 작아 충분히 샘플링 된 동선만으로도 전체 동선의 경향성을 유지하는 모습도 확인이 가능합니다.
마치며
지금까지 재식별 기술의 전반적인 내용과 함께 메이아이에서 재식별 기술을 활용하여 진행할 수 있는 분석 예시까지 다양한 내용에 대해 살펴보았습니다. 사실 상용화된 사례가 메이아이를 제외하고는 그렇게 많지 않은 만큼 동선 분석 기술 및 재식별 기술에 관해 간략하게 다루는 글이 많지 않은 편인데요.
이 글을 바탕으로 메이아이의 동선 분석 기술과 그 원리에 대해 조금이라도 도움이 되었기를 바랍니다 :)








