
안녕하세요, 메이아이의 ML Engineer 정재민입니다.
오늘은 딥러닝 모델을 가속화하는 TensorRT에 대해 소개하려고 합니다. 본문으로 들어가기에 앞서, 아래 링크에 접속한 후에 사용하고자 하는 TensorRT의 버전을 클릭하면 필요한 cuda 버전을 찾으실 수 있음을 알립니다.
TensorRT이란?
TensorRT는 엔비디아에서 개발한 추론에 최적화되어있는 SDK입니다. 자신이 개발한 모델을 TensorRT로 추론해 보면 엄청난 속도 향상을 가져올 수 있습니다. 그럼 어떻게 TensorRT는 빠르게 추론이 가능할까요? 추론하고자 하는 모델에 대해 TensorRT는 아래와 같이 작업합니다.
- Elimination of layers whose outputs are not used.
- Elimination of operations which are equivalent to no-op
- The fusion of convolution, bias and ReLU operations
- Aggregation of operations with sufficiently similar parameters and the same source tensor (for example, the 1x1 convolutions in GoogleNet v5’s inception module)
- Merging of concatenation layers by directing layer outputs to the correct eventual destination.
TensorRT를 설치하기 이전에 Pytorch 버전과 관련된 이슈가 많은데요. 저는 Pytorch 1.3 버전 이상일 경우는 TensorRT 7 버전, Pytorch 1.2 버전 이하일 경우는 TensorRT 6 버전을 사용하시기를 추천합니다. 참고로 저는 Pytorch 1.3 / TensorRT 7을 사용합니다. NGC에 TensorRT 나 Pytorch 도커 이미지를 사용하는 것을 권장합니다.
Exporting a model from pytorch to ONNX
Pytorch를 곧바로 TensorRT로 바꾸는 일은 너무 힘든 일입니다. 그렇기 때문에 ONNX로 추출한 뒤 파싱하여 자동으로 바꾸겠습니다. 먼저 아주 간단한 MNIST 분류 모델을 Pytorch 로 만들어 보겠습니다.
tqdm 을 이용하면 초당 이터레이션이 얼마나 도는지 확인할 수 있습니다. 제 경우에는 2640.29it/s 가 걸리는군요! 이제 ONNX로 추출해 봅시다! ONNX는 파이토치 튜토리얼에 나와있습니다.
TensorRT backend for ONNX
이번 포스트에서는 onnx 나 tensorrt에서 지원하지 않는 op, layer에 대해서는 다루지 않습니다. 그럼 위에서 추출한 onnx 파일로 TensorRT 추론하기에 앞서 다음 코드를 봅시다.
해당 코드는 tensorrt sample 예제에 공통으로 쓰이는 것입니다. cuda 에 관련된 것들이 많은데 주석을 보고 이런 기능을 하는구나 정도로만 이해하고 넘어가면 될 것 같습니다.
우선 위에 필요한 클래스와 함수를 선언하고 아래를 저와 같이 맞춰 주세요. builder에 관련된 것은 여기로 이동하여 확인할 수 있습니다. 그 외에는 위 출력문을 통해 어떤 기능을 하는 것인지 알 수 있습니다.
해당 코드를 실행하기 위해서 필요한 것은 아까 exporting 했던 onnx 파일뿐 입니다! 실행해 봅시다!
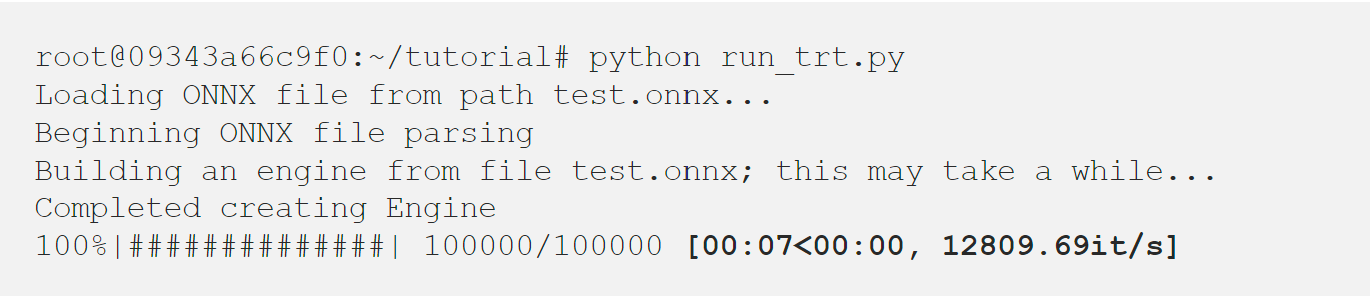
대략 5~6 배가 빨라졌네요. 이렇게 TensorRT는 딥러닝 모델을 리얼타임 서비스에 적용하려면 필수적인 요소입니다. 다음 포스트에서는 영상 처리의 대표적인 모델들을 가지고 지원하지 않는 op, layer에 대해 구성하고 TensorRT로 추론하도록 하겠습니다.








